
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 예스24
- geo
- AI 에이전트
- ChatGPT
- 실리콘밸리워크플로우
- AI네이티브
- 패스키
- github
- 커리어성장
- Antigravity
- 마운자로
- 이커머스트렌드
- 생산성혁명
- 위고비
- Gemini
- YouTrack
- swagger
- Github Copilot
- SEO
- AI에이전트
- 프론트엔드
- GA4
- 프롬프트 엔지니어링
- 가상시나리오
- GPT
- Passkey
- GTM
- 생산성
- AI
- Today
- Total
Beyond Frontend
인터넷은 왜 느려질까요? 당신의 클릭 한번이 겪는 놀라운 여정 본문

1. '느림'이라는 사용자 경험의 기술적 재구성
사용자가 체감하는 '인터넷이 느리다'는 감각은 매우 직관적이고 단일한 현상으로 느껴집니다. 화면이 하얗게 멈춰 있거나, 버튼 클릭에 반응이 없거나, 이미지가 끊기며 로딩되는 모든 경험은 이 한마디로 귀결됩니다. 하지만 소프트웨어 엔지니어링과 네트워크 아키텍처의 관점에서 이 현상을 분해하면, 이는 빛의 속도로 이동하는 패킷의 물리학적 한계, 서버 CPU의 스케줄링 정책 실패, 혹은 브라우저 렌더링 엔진의 비효율적인 파이프라인 처리 등 다차원적인 원인들이 얽힌 복합적인 결과물임을 알 수 있습니다.
본 백서는 사용자의 클릭부터 화면에 픽셀이 그려지기까지의 전 과정을 추적하며 각 단계의 기술적 병목 현상을 심층적으로 분석합니다. 우리는 먼저 보이지 않는 네트워크 기저에서 벌어지는 프로토콜 간의 전쟁을 살펴보고, 서버 내부의 침묵 속에서 발생하는 자원 경쟁을 분석하며, 마지막으로 브라우저가 데이터를 시각적 결과물로 변환하는 마지막 단계를 해부할 것입니다.
이 분석을 통해 우리는 '느림'이라는 단일한 사용자 경험 이면에 숨겨진 복잡한 기술적 인과관계를 이해하고, 이를 '빠름'으로 전환하기 위한 엔지니어링적 통찰을 제공하고자 합니다. 본문은 네트워크, 서버, 그리고 브라우저라는 세 가지 핵심 레이어로 구성하여 각 영역의 병목 현상을 체계적으로 탐구할 것입니다.
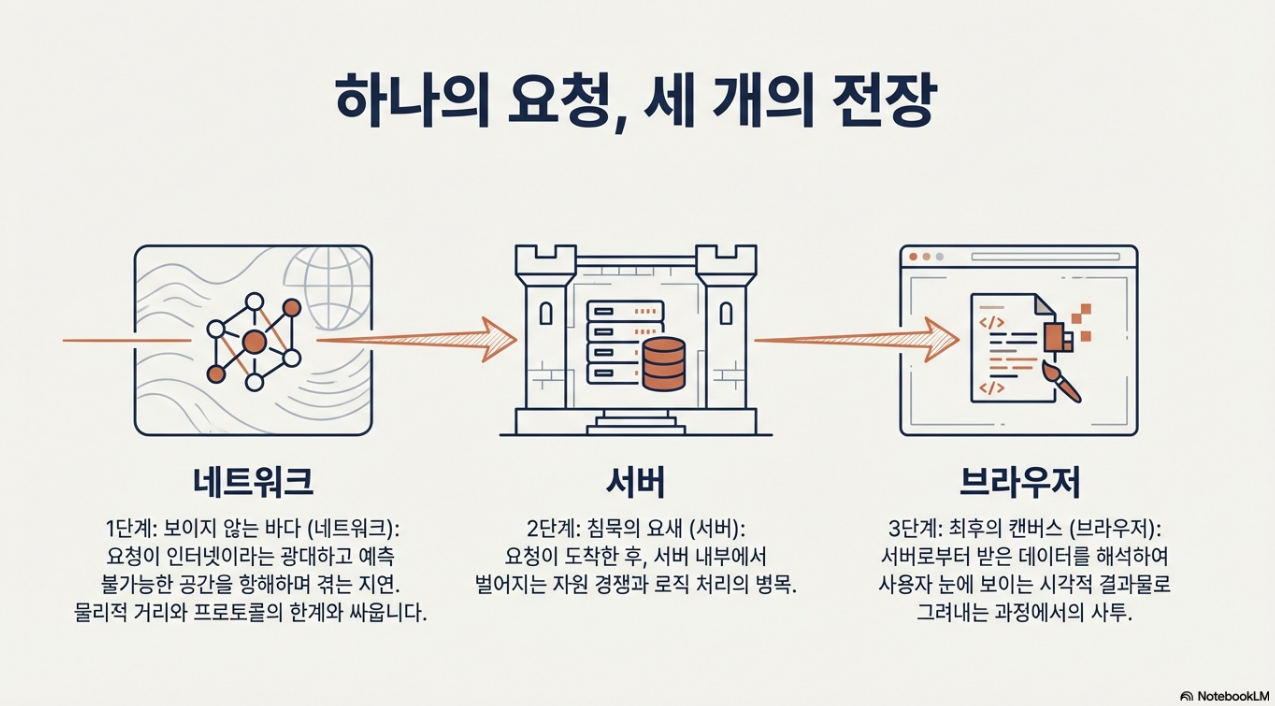
2. 네트워크 레이어의 심층 분석: 보이지 않는 연결의 비용
사용자가 인지하는 초기 '대기 시간'의 대부분은 데이터가 사용자의 기기에 도달하기도 전에 발생하는 네트워크 레이어에서 비롯됩니다. 데이터 패킷의 물리적 여정과 이를 관장하는 프로토콜의 설계 자체가 지연의 근본적인 원인이 됩니다. 이 장에서는 웹 요청의 첫 번째 관문인 네트워크에서 발생하는 숨겨진 비용을 분석합니다.
2.1. 초기 연결 설정의 숨겨진 비용
웹 요청의 시작은 데이터를 전송하기에 앞서 브라우저와 서버 간의 신뢰할 수 있는 연결을 수립하는 과정입니다. 이 과정에서 발생하는 여러 번의 '핸드셰이크(Handshake)'는 눈에 보이지 않는 지연을 누적시키는 첫 번째 병목 구간입니다.
2.1.1. DNS 조회 지연
모든 웹 통신은 www.example.com과 같은 도메인 이름을 서버의 실제 주소인 IP 주소로 변환하는 DNS(Domain Name System) 조회 과정에서 시작됩니다. 이 과정은 구글(8.8.8.8)이나 클라우드플레어(1.1.1.1) 같은 퍼블릭 DNS를 통해 이루어지며, 짧게는 수 밀리초(ms)에서 길게는 수백 밀리초까지 소요될 수 있습니다. 특히 레이턴시가 불안정한 모바일 네트워크 환경에서는 이 지연이 더욱 두드러지며, 사용자는 화면에 아무것도 뜨지 않은 채 "찾는 중..."이라는 메시지만 보게 됩니다. 브라우저는 DNS 프리패치(Prefetch)나 OS 수준의 캐싱을 통해 지연을 완화하지만, 캐시가 없거나 만료된 경우(Cache Miss) 발생하는 지연은 피할 수 없는 첫 번째 허들입니다.
2.1.2. TCP 3-Way Handshake의 오버헤드
IP 주소를 확보한 후, 데이터 전송의 신뢰성을 보장하기 위해 브라우저와 서버는 TCP(Transmission Control Protocol) 연결을 수립합니다. 이 과정은 다음과 같은 3단계 확인 절차를 거칩니다.
- SYN: 클라이언트가 서버에 연결 요청 신호를 보냅니다.
- SYN-ACK: 서버가 요청을 수락하며 응답 신호를 보냅니다.
- ACK: 클라이언트가 최종 확인 신호를 보냅니다.
이 3단계 핸드셰이크는 최소 **1.5 RTT(Round Trip Time, 왕복 시간)**를 소모합니다. 예를 들어, 서울에서 뉴욕에 위치한 서버에 접속한다면 빛의 속도로도 왕복에 약 200ms 이상이 소요됩니다. 즉, 사용자는 아무런 데이터도 받지 못한 채 0.2초를 허비하게 됩니다.
2.1.3. TLS 핸드셰이크의 보안 비용
현대 웹의 표준인 HTTPS(HTTP Secure)는 TCP 연결 위에 TLS(Transport Layer Security) 암호화 계층을 추가로 수립해야 합니다. 이 과정에서 암호화 키를 교환하고 인증서를 검증하며 추가적인 지연이 발생합니다.
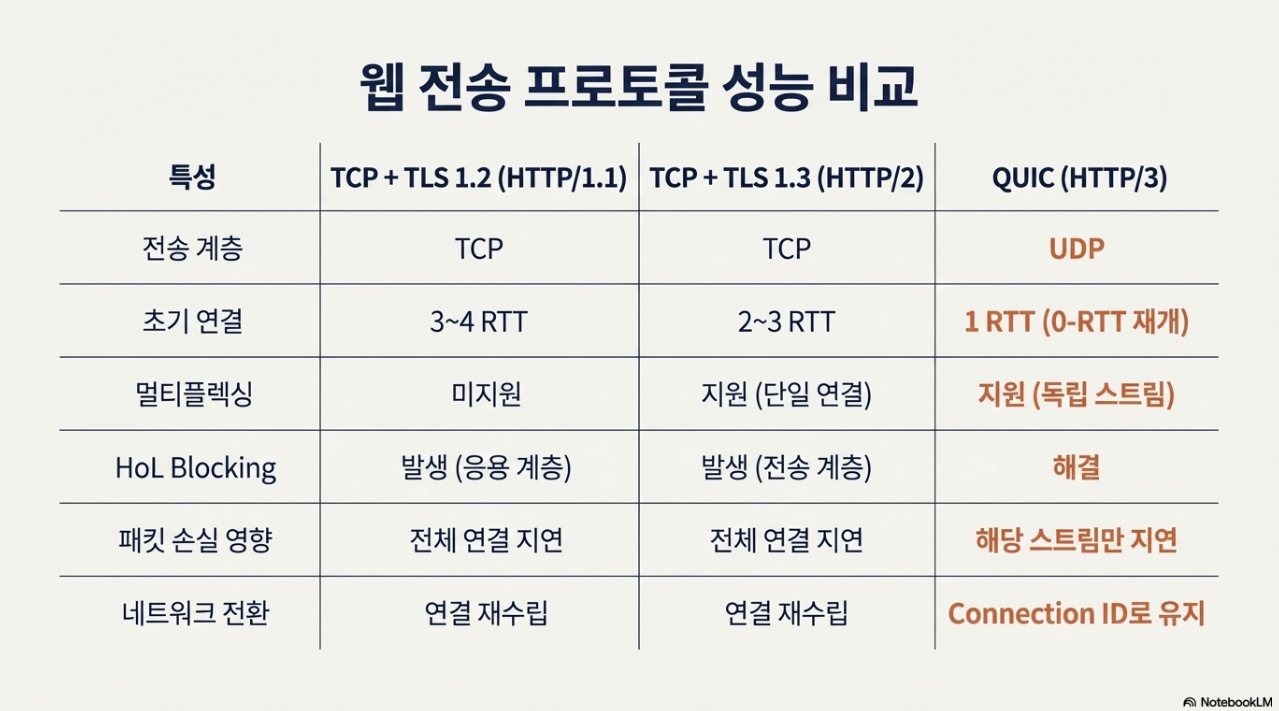
- TLS 1.2: 널리 사용되던 TLS 1.2는 키 교환을 위해 2 RTT를 추가로 요구했습니다. TCP 핸드셰이크와 결합하면 초기 연결에만 총 3-4 RTT가 소요되어, 사용자는 클릭 후 응용 프로그램 데이터를 요청하기도 전에 0.5초 이상의 지연을 겪게 될 수 있었습니다.
- TLS 1.3: 최신 표준인 TLS 1.3은 이 과정을 1 RTT로 단축했습니다. 또한, 이전에 접속했던 서버와는 핸드셰이크 과정 없이 데이터를 전송할 수 있는 '0-RTT 재개' 기능을 도입하여 초기 연결 속도를 획기적으로 개선했습니다.

2.2. 전송 프로토콜의 진화와 구조적 병목
연결이 수립된 후, 데이터를 교환하는 HTTP 프로토콜의 방식은 웹사이트의 실제 '반응 속도'를 결정합니다. 프로토콜의 구조적 한계는 성능 저하의 핵심 원인이 될 수 있습니다.
2.2.1. HTTP/1.1과 HTTP/2의 TCP Head-of-Line Blocking
과거 HTTP/1.1은 하나의 연결에서 요청을 순차적으로 처리했기 때문에, 브라우저는 이 한계를 극복하기 위해 도메인당 최대 6개의 TCP 연결을 동시에 여는 전략을 사용했습니다. 이를 개선한 HTTP/2는 **멀티플렉싱(Multiplexing)**을 도입하여 단일 TCP 연결 내에서 여러 요청과 응답(스트림)을 동시에 처리할 수 있게 했습니다.
하지만 HTTP/2 역시 TCP 위에서 동작한다는 태생적 한계를 가집니다. 바로 TCP Head-of-Line (HoL) Blocking입니다. TCP는 패킷의 순서를 엄격하게 보장하므로, 만약 여러 스트림 중 하나의 스트림에 속한 패킷 하나가 유실되면 TCP 계층에서는 해당 패킷이 재전송될 때까지 그 뒤에 오는 모든 스트림의 패킷 전송을 중단시킵니다. 이는 마치 '고속도로 1차선에서 사고가 나면 모든 차선이 정체되는 현상'과 같습니다. 이는 불안정한 와이파이나 이동 중인 모바일 네트워크에서 웹사이트 로딩이 뚝뚝 끊기거나 멈추는 현상의 주범입니다.

2.2.2. QUIC과 HTTP/3의 패러다임 전환
HTTP/3는 TCP 대신 UDP 기반의 QUIC(Quick UDP Internet Connections) 프로토콜을 채택하여 HoL Blocking 문제를 근본적으로 해결했습니다. QUIC은 다음과 같은 혁신적인 특징을 가집니다.
- 진정한 멀티플렉싱: 각 스트림이 전송 계층에서부터 독립적으로 처리됩니다. 하나의 스트림에서 패킷 손실이 발생해도 다른 스트림의 전송에는 영향을 주지 않습니다.
- 연결 마이그레이션(Connection Migration): 사용자가 Wi-Fi에서 LTE로 네트워크를 전환할 때 IP 주소가 바뀌어도, QUIC은 고유한 'Connection ID'를 사용하여 연결을 끊지 않고 유지합니다. 이는 모바일 환경에서의 끊김 없는 사용자 경험을 제공합니다.
- 1-RTT 핸드셰이크: 전송 계층 설정과 TLS 1.3 암호화 핸드셰이크를 1 RTT만으로 통합하여 초기 연결 지연을 최소화합니다.

2.2.3. 웹 전송 프로토콜 비교 분석
각 프로토콜의 성능 특성은 다음 표와 같이 요약할 수 있습니다.
2.3. 혼잡 제어 알고리즘과 네트워크 품질의 역설
네트워크 대역폭을 얼마나 효율적으로 활용할지 결정하는 '혼잡 제어 알고리즘' 역시 체감 속도에 큰 영향을 미칩니다.
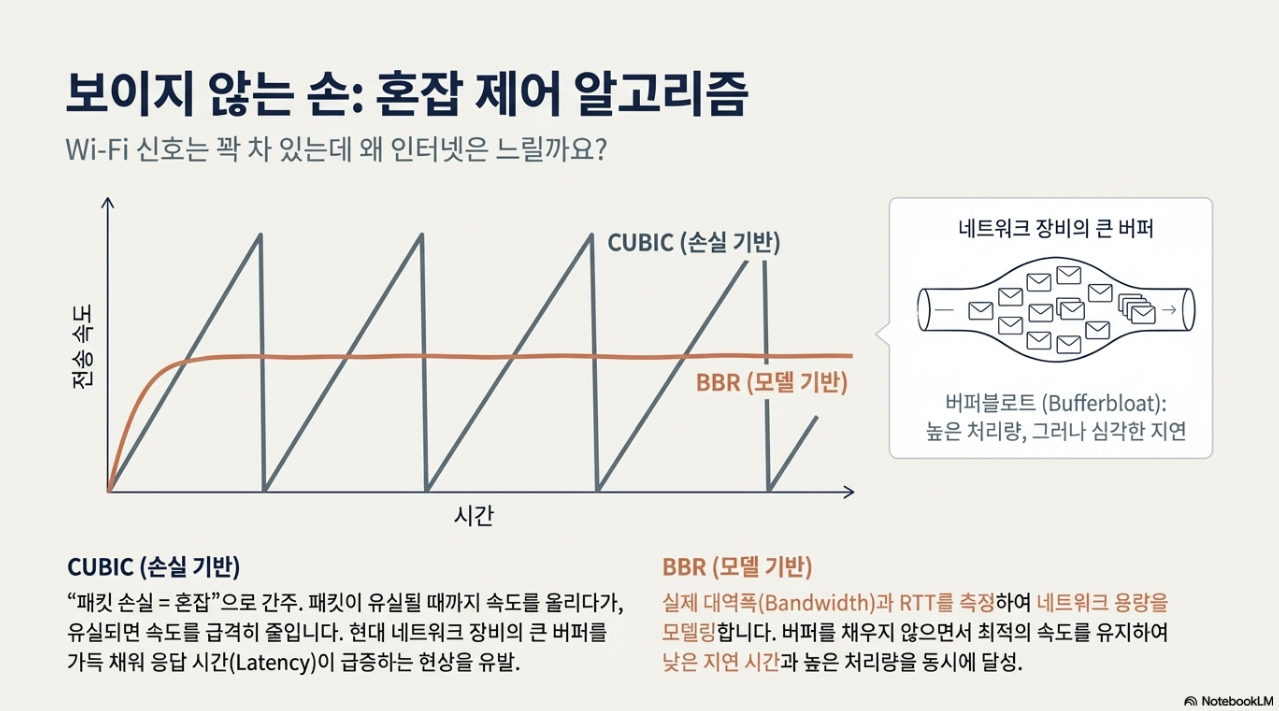
2.3.1. CUBIC의 손실 기반 제어와 버퍼블로트(Bufferbloat)
대부분의 운영체제에서 기본으로 사용하는 CUBIC 알고리즘은 **'패킷 손실 = 네트워크 혼잡'**이라는 가정하에 동작합니다. 패킷 손실이 감지되면 네트워크가 혼잡하다고 판단하고 전송 속도를 급격히 줄입니다. 하지만 현대 네트워크 장비의 거대한 버퍼는 이 가정을 무력화시킵니다. CUBIC은 패킷 손실 직전까지 이 버퍼를 데이터로 가득 채우게 되는데, 이를 버퍼블로트(Bufferbloat) 현상이라 합니다. 이로 인해 전송량(Throughput)은 높게 유지되지만, 패킷이 버퍼에서 대기하는 시간이 길어져 실제 응답 시간(Latency)은 급격히 저하되는 문제가 발생합니다.
2.3.2. BBR의 모델 기반 제어 혁신
Google이 개발한 BBR(Bottleneck Bandwidth and Round-trip propagation time) 알고리즘은 패킷 손실 대신 **대역폭(Bandwidth)과 왕복 시간(RTT)**을 직접 측정하여 네트워크 파이프를 모델링합니다. BBR은 불필요하게 버퍼를 채우지 않으면서 네트워크가 처리할 수 있는 최적의 속도로 데이터를 전송합니다. 실험 결과에 따르면 패킷 손실률 1% 환경에서 CUBIC은 속도가 70% 이상 급락하는 반면, BBR은 거의 영향을 받지 않고 높은 속도를 유지했습니다. 이는 "Wi-Fi 신호는 강한데 인터넷이 느린" 현상을 해결하는 핵심 기술 원리입니다.
네트워크 레이어에서의 모든 병목을 해결하여 데이터가 클라이언트에 성공적으로 도달했더라도, 서버의 응답 자체가 느리다면 모든 노력은 수포로 돌아갑니다. 다음 장에서는 서버 내부에서 발생하는 침묵의 시간에 대해 분석합니다.
3. 서버 레이어의 심층 분석: 응답을 기다리는 침묵의 시간
서버가 클라이언트의 요청을 받고 첫 번째 데이터 바이트를 반환하기까지 걸리는 시간을 **TTFB(Time To First Byte)**라고 합니다. TTFB가 길어지는 것은 사용자가 '먹통' 현상을 경험하는 주된 원인입니다. Google은 TTFB 200ms 이하를 권장하며, 600ms 이상은 '느림'으로 간주합니다. 이 시간은 서버 내부의 복잡한 연산, 데이터베이스 조회, 아키텍처 비효율성을 얼마나 잘 제어하는가에 달려 있습니다.

3.1. 서버 아키텍처와 동시성 처리의 병목
서버가 다수의 동시 요청을 처리하는 방식의 차이는 성능 저하의 직접적인 원인이 될 수 있습니다.
3.1.1. 스레드 기반 모델의 '스레드 풀 고갈'
Java/Tomcat과 같은 전통적인 웹 서버는 '요청당 스레드(Thread-per-Request)' 모델을 사용합니다. 미리 생성된 스레드 풀(예: 200개) 내에서 각 요청을 개별 스레드에 할당합니다. 만약 데이터베이스 조회와 같은 블로킹(Blocking) I/O 작업으로 인해 200개의 스레드가 모두 응답 대기 상태에 빠지면, 201번째 요청은 가용한 스레드가 생길 때까지 대기 큐에서 무한정 기다려야 합니다. 이 '스레드 풀 고갈(Thread Pool Starvation)' 현상은 서버가 다운된 것처럼 보이게 만듭니다.
3.1.2. 이벤트 기반 모델의 '이벤트 루프 차단'
Node.js와 같은 서버는 '싱글 스레드 이벤트 루프' 모델을 사용해 뛰어난 동시성을 자랑합니다. 하지만 이는 치명적인 약점을 내포합니다. 만약 JSON.parse로 거대한 파일을 처리하거나, 복잡한 암호화 연산, 긴 for 루프와 같이 CPU를 많이 소모하는 작업이 메인 스레드에서 실행되면, 해당 작업이 끝날 때까지 이벤트 루프 전체가 멈추게 됩니다. 이 '이벤트 루프 차단(Event Loop Blocking)' 현상은 단 하나의 비효율적인 요청이 서버 전체를 마비시키는 결과를 초래하며, 특히 서버 사이드 렌더링(SSR) 구현 시 흔히 발생하는 실수입니다.
3.2. 데이터베이스 성능 저하의 주범들
애플리케이션의 비효율적인 로직은 결국 데이터베이스에 과부하를 유발하여 전체 시스템의 성능을 저하시킵니다.
3.2.1. N+1 쿼리 문제
ORM(Object-Relational Mapping)이나 GraphQL 사용 시 빈번하게 발생하는 문제입니다. 예를 들어, 사용자 목록을 조회(1번의 쿼리)한 후, 목록의 각 사용자(N명)에 대한 주문 정보를 가져오기 위해 N번의 추가 쿼리를 실행하는 경우가 대표적입니다. 사용자가 100명이면 총 101번의 쿼리가 발생합니다. 데이터베이스와 서버 간의 네트워크 왕복 시간(RTT)이 1ms라도 총 100ms 이상의 지연이 추가로 발생합니다. 데이터 양이 증가할수록 페이지 로딩 시간은 선형적으로 증가하여 결국 타임아웃으로 이어질 수 있습니다.
3.2.2. 인덱스 부재와 풀 테이블 스캔
데이터베이스 인덱스는 책의 '색인'과 같은 역할을 합니다. 인덱스가 없는 컬럼을 기준으로 데이터를 조회하면, 데이터베이스는 테이블의 모든 행을 처음부터 끝까지 스캔하는 **'풀 테이블 스캔(Full Table Scan)'**을 수행합니다. 데이터가 수백만 건에 이르면 이 작업은 수 초가 걸릴 수 있습니다. "개발 서버에서는 빨랐는데 운영 서버에서는 느려요"라는 현상의 주된 원인은 바로 데이터 양의 차이로 인해 인덱스 부재의 비효율성이 극대화되기 때문입니다.
3.3. 서버 사이드 렌더링(SSR)과 하이드레이션의 '불쾌한 골짜기'
SSR은 초기 로딩 속도 향상에 기여하는 훌륭한 기술이지만, '하이드레이션(Hydration)' 과정에서 새로운 성능 문제를 야기할 수 있습니다. 하이드레이션은 서버가 생성한 정적 HTML에 클라이언트의 JavaScript가 동적 기능을 결합하는 과정입니다.
만약 서버가 렌더링한 HTML 구조와 클라이언트의 JavaScript가 실행된 결과물이 일치하지 않으면, React와 같은 프레임워크는 UI의 일관성을 맞추기 위해 전체 컴포넌트를 클라이언트에서 다시 그리는 비효율적인 작업을 수행합니다. 이 순간 사용자는 '화면은 보이는데 버튼을 눌러도 반응하지 않는' 묘한 멈춤 현상, 즉 **'불쾌한 골짜기(Uncanny Valley)'**를 경험하게 됩니다. 시각적으로는 완성되었으나 기능적으로는 죽어있는 이 상태는 실제 상호작용 가능 시점인 **TTI(Time to Interactive)**를 지연시키는 주된 원인이 됩니다.
서버가 성공적으로 빠른 응답을 생성했더라도, 최종 성능은 이 데이터를 사용자가 볼 수 있는 시각적 결과물로 만드는 브라우저의 손에 달려 있습니다. 마지막으로 브라우저 레이어의 병목 현상을 살펴보겠습니다.
4. 브라우저 레이어의 심층 분석: 픽셀을 그리는 마지막 여정
데이터가 브라우저에 도착하면, 0과 1의 비트스트림은 사용자가 인지하는 시각 정보로 변환되는 '렌더링 파이프라인'을 거칩니다. 이 마지막 여정에서의 비효율은 사용자가 직접적으로 느끼는 '화면 멈춤'이나 '깜빡임' 현상으로 이어지므로, 최종적인 사용자 경험의 질을 결정하는 매우 중요한 단계입니다.
4.1. 중요 렌더링 경로(Critical Rendering Path)의 병목
브라우저는 화면을 그리기 위해 다음과 같은 **중요 렌더링 경로(Critical Rendering Path, CRP)**를 따릅니다. HTML을 파싱하여 DOM 트리를, CSS를 파싱하여 CSSOM 트리를 생성하고, 이 둘을 결합해 렌더 트리를 만듭니다. 이후 각 요소의 위치와 크기를 계산(Layout)하고 최종적으로 화면에 픽셀을 채웁니다(Paint). 이 경로의 특정 단계가 지연되면 전체 렌더링이 중단됩니다.
4.1.1. 렌더 차단 리소스(CSS)의 영향
브라우저는 CSSOM 트리가 완성될 때까지 렌더링을 시작하지 않습니다. 이는 스타일이 적용되지 않은 콘텐츠가 잠시 노출되었다가 스타일이 입혀지며 화면이 번쩍이는 현상(FOUC, Flash of Unstyled Content)을 방지하기 위함입니다. 따라서 CSS 파일의 다운로드가 느려지면, 브라우저는 렌더링을 차단하고 사용자는 그 시간만큼 하얀 화면(Blank Page)을 보게 됩니다. 이를 해결하기 위해 페이지 렌더링에 필수적인 핵심 스타일(Critical CSS)만 HTML에 인라인으로 삽입하고 나머지는 비동기적으로 로드하는 전략이 사용됩니다.
4.1.2. 파서 차단 리소스(JavaScript)의 영향
HTML 문서를 파싱하던 브라우저는 <script> 태그를 만나면 파싱을 중단합니다. 그리고 즉시 스크립트 파일을 다운로드하여 실행합니다. 스크립트 실행이 완료될 때까지 HTML 파싱과 그에 따른 DOM 생성이 멈추는 이 '파서 차단' 현상은 초기 화면 렌더링을 지연시키는 핵심 원인 중 하나입니다. 만약 용량이 큰 JavaScript 파일이 문서 상단(<head>)에 위치한다면, 사용자는 스크립트가 로드되고 실행되는 동안 아무것도 없는 화면을 봐야만 합니다.
5. 빠름을 위한 종합적 접근
본문에서 분석한 바와 같이, '웹 성능 저하'는 단일 계층의 문제가 아닌, 전체 스택에 걸쳐 상호 의존적으로 발생하는 시스템적인 문제입니다. 사용자가 느끼는 '느림'은 각 계층의 병목들이 중첩되고 상호작용하며 나타나는 최종 결과물입니다.
- 네트워크 레이어에서는 핸드셰이크의 물리적 시간 비용과 패킷 손실 시 전체 스트림을 막는 TCP HoL Blocking, 그리고 구형 혼잡 제어 알고리즘의 비효율이 초기 지연을 지배합니다.
- 서버 레이어에서는 아키텍처 모델의 동시성 처리 한계(스레드 풀 고갈, 이벤트 루프 차단)와 데이터베이스 접근 패턴(N+1 쿼리, 인덱스 부재)의 비효율이 응답 시간을 결정합니다.
- 브라우저 레이어에서는 중요 렌더링 경로상의 차단 리소스들이 서버로부터 받은 데이터를 시각적 결과물로 변환하는 마지막 과정을 지연시킵니다.
결론적으로, 효과적인 성능 최적화는 단순히 QUIC과 같은 최신 기술을 도입하는 것을 넘어, 시스템 전반의 상호작용을 깊이 이해하고 병목을 진단하는 지속적인 엔지니어링 활동을 요구합니다. 네트워크에서 시작해 서버를 거쳐 브라우저에 이르는 데이터의 전 여정을 종합적으로 분석하고 개선할 때, 비로소 사용자에게 진정으로 '빠른' 경험을 제공할 수 있을 것입니다.
배경지식: 웹 성능 최적화의 핵심 개념
원본 자료는 사용자가 느끼는 '느림'이라는 감각이 네트워크, 서버, 브라우저 등 여러 기술적 병목 현상의 복합적인 결과임을 심층적으로 분석합니다. 이 자료를 100% 이해하기 위해 반드시 알아야 할 세 가지 핵심 개념, 즉 RTT, tcp/udp, 그리고 웹 성능 지표(LCP, TTI)에 대해 친절하게 설명해 드립니다.
1. RTT (Round Trip Time): 데이터의 왕복 시간
RTT, 즉 왕복 시간(Round Trip Time)은 네트워크 성능을 측정하는 가장 기본적인 단위입니다. 쉽게 말해, 내가 보낸 데이터 패킷이 서버까지 갔다가 응답을 받아 다시 나에게 돌아오는 데 걸리는 총 시간을 의미합니다.
- RTT의 비유:
- RTT는 '서울에서 부산까지 편지를 보냈다가 답장을 받는 데 걸리는 시간'과 같습니다. 편지를 보내는 데 1시간, 답장을 받는 데 1시간이 걸렸다면 RTT는 2시간이 됩니다.
- 웹에서는 이 시간이 밀리초(ms) 단위로 측정됩니다. 서울에서 뉴욕 서버까지는 빛의 속도로 왕복해도 약 200ms 이상이 소요되는데, 이는 물리적인 한계입니다.
- 웹 성능에서 RTT가 중요한 이유:
- 초기 연결 지연: 웹사이트에 접속할 때, DNS 조회나 TCP 3-Way 핸드셰이크 같은 초기 연결 과정에서 RTT가 여러 번 소모됩니다.
- 예를 들어, TCP 연결만으로 최소 1.5 RTT가 소모되며, TLS 1.2를 사용하면 3~4 RTT가 소모되어 사용자는 아무 데이터도 받지 못한 채 0.5초 이상을 허비할 수 있습니다.
- TTFB (Time To First Byte): 서버가 첫 번째 바이트를 보내는 시간(TTFB) 역시 RTT의 영향을 받습니다. 서버가 데이터베이스에 쿼리를 보낼 때도 RTT가 발생하며, 이 시간이 길어지면 사용자는 '먹통' 현상을 겪게 됩니다.
- 초기 연결 지연: 웹사이트에 접속할 때, DNS 조회나 TCP 3-Way 핸드셰이크 같은 초기 연결 과정에서 RTT가 여러 번 소모됩니다.
2. TCP와 UDP: 신뢰성 대 속도의 딜레마
- TCP (Transmission Control Protocol): 신뢰성의 완벽주의자
- 특징: 데이터를 보낼 때 순서 보장, 손실 복구, 흐름 제어를 철저히 수행합니다.
- 비유: 택배를 보낼 때, 반드시 수신 확인 서명을 받고, 순서대로 배달하며, 분실 시 재발송을 보장하는 서비스와 같습니다.
- 단점: 이 신뢰성을 확보하기 위해 3-Way 핸드셰이크 같은 복잡한 절차를 거치며, 패킷 하나라도 손실되면 전체 연결이 멈추는 Head-of-Line (HoL) Blocking 현상이 발생합니다.
- 주요 사용처: 웹 브라우징(HTTP/1.1, HTTP/2), 이메일, 파일 전송(FTP) 등 데이터의 완전성이 중요한 서비스.
- UDP (User Datagram Protocol): 속도의 실용주의자
- 특징: 신뢰성이나 순서 보장을 포기하는 대신, 최대한 빠르게 데이터를 전송합니다.
- 비유: 엽서를 보내는 것과 같습니다. 엽서가 중간에 분실되거나 순서가 뒤바뀌어도 재전송을 요청하지 않고 계속 보냅니다.
- 장점: 오버헤드가 적어 매우 빠르며, HoL Blocking이 발생하지 않습니다. 하나의 패킷이 손실되어도 다른 패킷의 전송에는 영향을 주지 않습니다.
- 주요 사용처:
- 실시간 스트리밍 (Live Streaming): 줌(Zoom)이나 스포츠 중계처럼 '지금 현재'의 정보가 중요하고, 1초 전의 잃어버린 프레임보다 끊기지 않는 흐름이 중요한 경우에 사용됩니다.
- HTTP/3 (QUIC): UDP 위에 TCP의 장점(신뢰성, 암호화)을 재구현하여, TCP의 HoL Blocking 문제를 근본적으로 해결했습니다.
TCP와 UDP의 비교 (웹 성능 관점)
| 특성 | TCP (신뢰성) | UDP (속도) |
| 연결 방식 | 연결 지향 (핸드셰이크 필수) | 비연결 지향 (핸드셰이크 불필요) |
| 신뢰성 | 높음 (손실 시 재전송) | 낮음 (손실 무시) |
| 순서 보장 | 엄격히 보장 | 보장하지 않음 |
| 웹 성능 병목 | Head-of-Line Blocking 발생 | HoL Blocking 해결 |
| 주요 사용처 | VOD (넷플릭스), 파일 다운로드 | Live Streaming, HTTP/3 |
3. 웹 성능 지표: LCP와 TTI (Core Web Vitals)
- Core Web Vitals란 무엇인가?
- 구글이 웹페이지의 로딩 성능, 상호작용성, 시각적 안정성을 측정하기 위해 정의한 세 가지 핵심 지표입니다.
- 이 지표들은 단순히 기술적인 속도뿐만 아니라, 사용자가 실제로 페이지를 얼마나 빠르고 편안하게 느끼는지를 측정하는 데 초점을 맞춥니다.
- LCP (Largest Contentful Paint): 최대 콘텐츠 렌더링 시간
- 정의: 페이지 로딩이 시작된 시점부터 가장 큰 이미지나 텍스트 블록이 화면에 완전히 표시되는 데 걸리는 시간입니다.
- 중요성: 사용자가 페이지에 접속했을 때 "뭔가 로딩되고 있다"고 느끼는 시점을 측정합니다. 이 시간이 길면 사용자는 '흰 화면'을 오래 보게 됩니다.
- 최적화 연결점: 자료에서 언급된 레이지 로딩의 함정은 LCP를 늦추는 대표적인 실수입니다.
- TTI (Time to Interactive): 상호작용 가능 시간
- 정의: 페이지가 완전히 렌더링되어 사용자가 버튼을 클릭하거나 스크롤하는 등의 상호작용이 가능해지는 데 걸리는 시간입니다.
- 중요성: 화면은 다 떴는데 버튼을 눌러도 반응이 없는, 이른바 '불쾌한 골짜기(Uncanny Valley)' 현상을 측정합니다.
- 최적화 연결점: 서버 사이드 렌더링(SSR) 후 하이드레이션 과정에서 자바스크립트가 메인 스레드를 점유하여 TTI를 늦추는 것이 주된 원인입니다.
'IT Insights' 카테고리의 다른 글
| AI 시대, 우뇌 경제와 소프트 스킬 (0) | 2025.12.27 |
|---|---|
| 실시간 웹의 부상: 기술, 경험, 비즈니스를 관통하는 패러다임의 전환 (1) | 2025.12.21 |
| QR, NFC, 바코드 비교 분석 (1) | 2025.12.21 |
| 스타링크가 여는 우주 인터넷 시대 (0) | 2025.12.21 |
| Gemini 3 활용법 (0) | 2025.12.21 |



